Представьте, вы получили письмо по электронной почте. Написать мог кто угодно: подрядчик, книжный интернет-магазин, другие сайты и сервисы.
Зачастую для понятного представления всей информации в письмах используются таблицы. Именно в этом кроется боль наших пользователей: из таблиц тяжело выудить нужную информацию и добавить её в ПланФикс, например в инфоблок. И это проблема.
Раньше такие проблемы смельчаки решали через сложные регулярные выражения, т.е. нужны знания программирования, много времени и тестов. Всё это слишком долго и тяжело настраивается.
Для упрощения работы мы сделали первый шаг к тому, чтобы научить ПланФикс разбирать на инфоблоки данные из html-таблиц в письмах.

Пока сложно и непонятно? Ничего, дальше будет ещё хуже.
Шучу, давайте разбираться 🙂
Представьте, у вас интернет-магазин. Клиент сделал заказ — в ПланФикс пришло соответствующее уведомление:

По клику картинка откроется в новом окне и большем размере.
Обратите внимание, данные для обработки заказа разбросаны по нескольким таблицам. Так вот, мы научили ПланФикс «гулять» по ячейкам и собирать в инфоблоки нужные данные, которые затем можно добавить в поля задачи или аналитику.
Всё настраивается в правилах разбора почты. Во второй пункт мы добавили новый формат извлечения данных «HTML-таблица»:

Разбор письма
Алгоритм настройки следующий:
- Получаем письмо в ПланФикс.
- Копируем адрес созданной задачи из адресной строки браузера или прямо в ПланФиксе.
- Настраиваем почтовое правило.
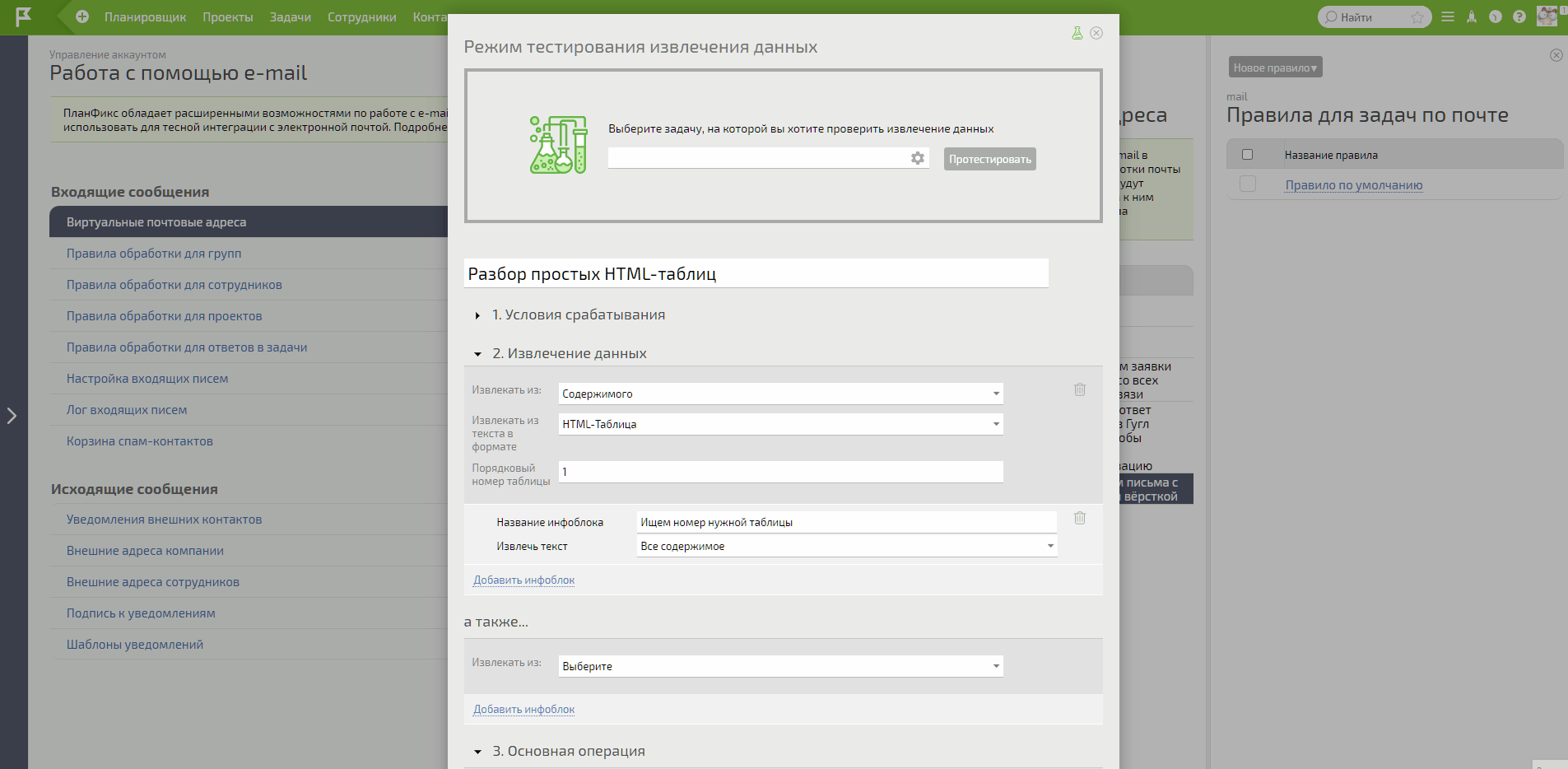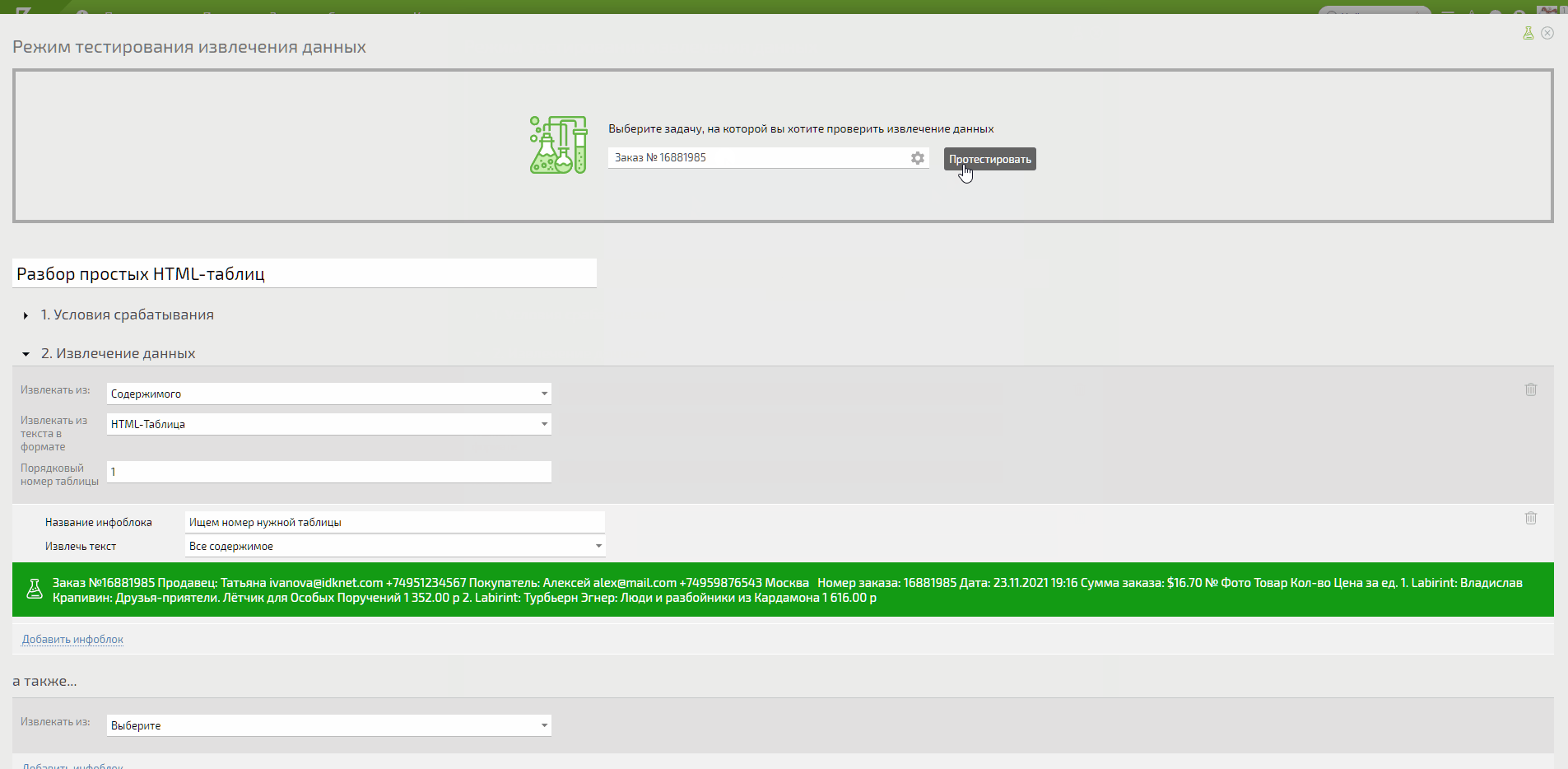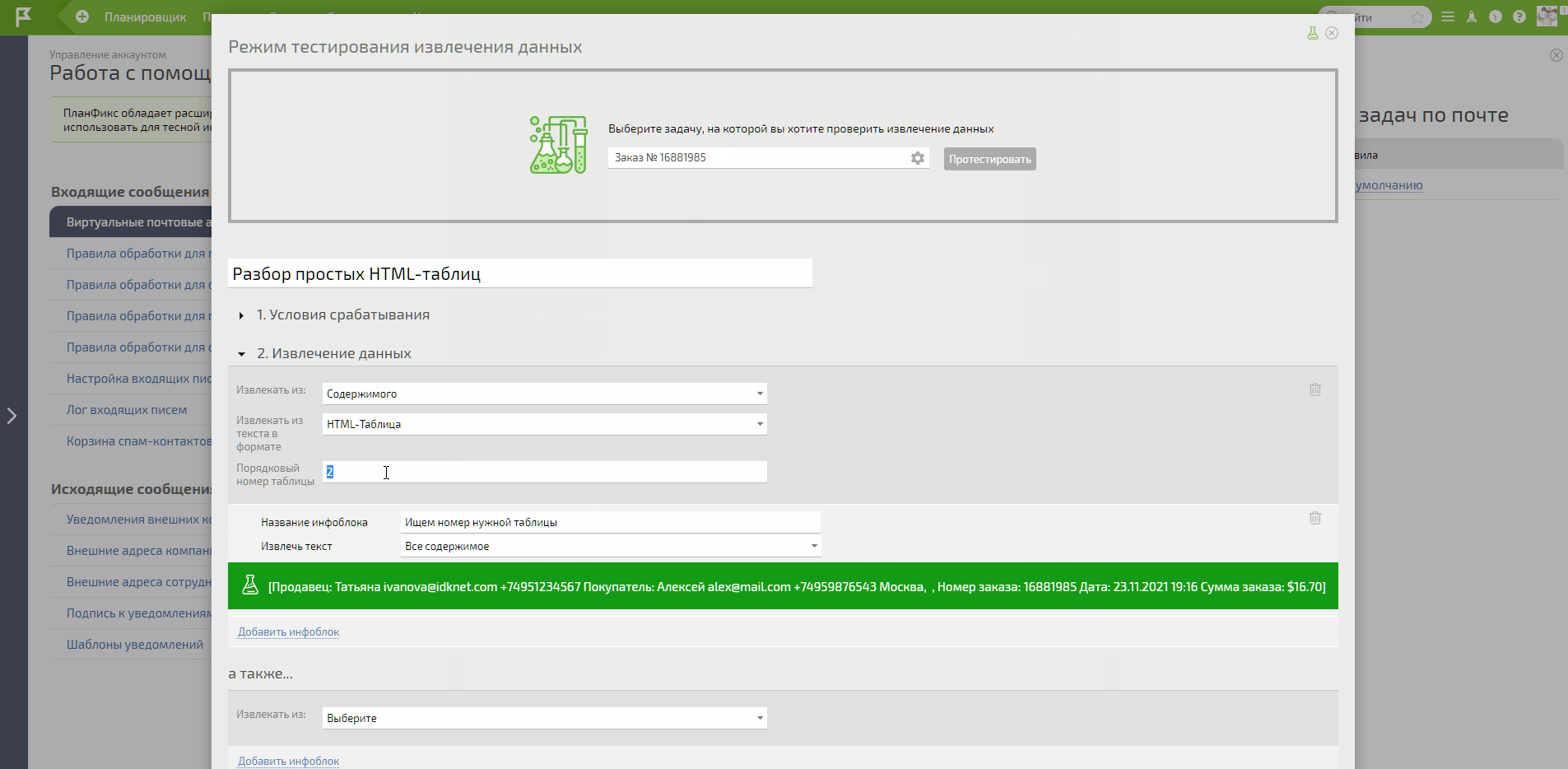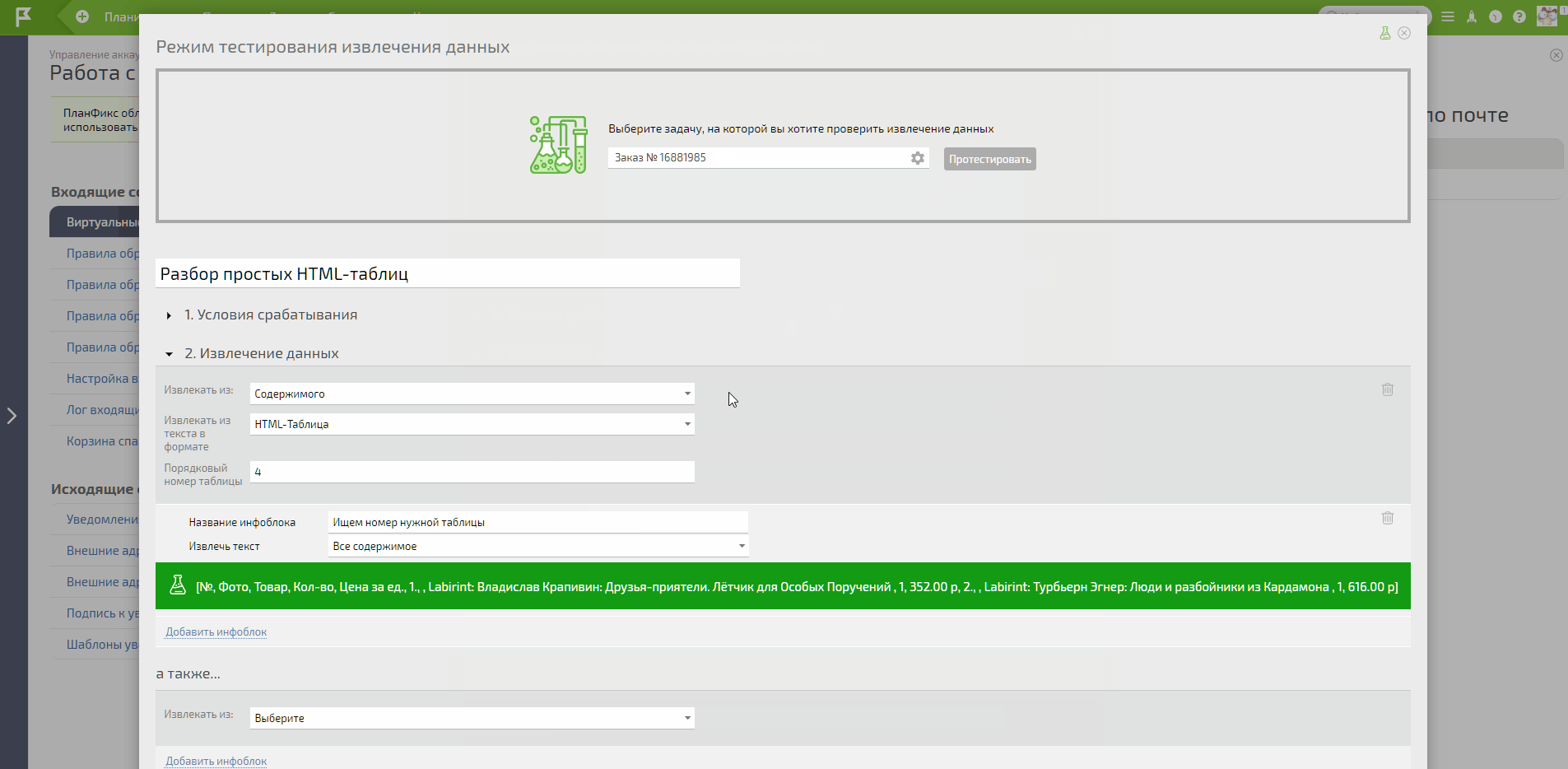
- Находим номер таблицы для разбора, используя тестирование.
- Добавляем нужные инфоблоки, другие операции и сохраняем правило.
- Повторно отправляем тестовое письмо, убеждаясь в правильности разбора.
Подробнее остановлюсь на извлечении данных. Проблема, с которой вы обязательно столкнётесь – поиск нужного номера таблицы.
Если вы знаете HTML, вам не составит особого труда найти нужный по порядку тег <table>.
Для всех остальных покажу универсальный способ поиска порядкового номера таблицы. На этом этапе вам понадобится заранее скопированный адрес созданной задачи, о которой я писал во втором пункте алгоритма настройки.
Будем искать порядковый номер вот этой таблицы:

Сделал для вас небольшую гифку, которая демонстрирует процесс поиска нужного номера таблицы. Гифку лучше открыть в отдельном окне, кликнув на неё:
По клику картинка откроется в новом окне и большем размере.
В итоге обычным перебором находим нужный номер таблицы. В моём примере таблица с нужными данными под номером 4.
Далее переходим к следующему этапу — отправляем ПланФикс «гулять» по ячейкам найденной таблицы:

Даём имена инфоблокам и говорим ПланФиксу из какого столбца и строки забирать нужную информацию.
Обратите внимание:
- Порядковый номер таблицы – это таблица по порядку нахождения тега <table> в HTML-письме.
- Всё содержимое – вариант нужен прежде всего, чтобы проверить в ту ли таблицу вы попали, т.к. часто в письмах вёрстка тоже таблицами. Это усложняет поиск нужного номера.
- Все строки — вариант нужен для того, чтобы из данных таблиц потом создавать записи аналитик.
- Последняя строка — вариант нужен, чтобы получить итог в таблице.
- Конкретный столбец и конкретная строка — вариант нужен в тех случаях, когда письмо свёрстано таблицей, а нужные данные, например имя или телефон, лежат в конкретной ячейке в таблице.
Последний вариант «Конкретный столбец и конкретная строка» разберем на примере получения номера заказа из письма:

Настройка в правиле почты такая:

Обратите внимание, сначала я подобрал порядковый номер таблицы (№ 3), а затем указал из какого столбца (2) и какой строки (1) забрать данные.
Вот и всё. Надеюсь, теперь вы сможете самостоятельно настроить подобный разбор уже на своих примерах.
Подытожим
Мы сделали первый шаг в попытке научить ПланФикс разбирать подобные письма. Всё, что смогли придумать — протестировали, но бывает всякое.
Например, наткнулись на случай, когда данные внутри таблицы расположены не в ячейке, а в другой отдельной таблице, состоящей из одного поля — получается таблица в ячейке таблицы. В итоге визуально человек видит одну таблицу, а по факту это набор несвязанных между собой таблиц. В этом случае будут сложности с извлечением данных по строкам – они просто не соберутся в кучку. Учитывайте этот момент при разборе.
Помните, о любой неожиданной работе системы можно смело писать в Службу поддержки.
А вообще, разбирать данные из таблиц оказалось очень увлекательно — столько всякой автоматики можно настроить. Поэкспериментируйте и обязательно напишите в комментариях, как вам новинка 🙂
Не забывайте о наших социальных сетях: ВКонтакте, Telegram, Facebook, Twitter и YouTube-канал. Там появляются новости о доработках и новинках. Подпишитесь, чтобы ничего не пропустить.

Ожидать ли возможность разбирать данные внутри ячейки от метки до метки и от метки до конца строки?
Например, в названии товара может быть приписан артикул, это не надо извлекать
Название товара (Артикул: ххх)
Тут бы помогло правило извлечения данных от метки с пустым значением до метки ” (Артикул:”
Алексей, если будут ещё запросы на такую доработку – будем что-то придумывать. Пока непонятно, как это уместить в общем интерфейсе, чтобы никого не запутать настройками 🙂
Добрый!
Присоединяюсь к просьбе Алексея. Было бы хорошо иметь описанную им возможность.
Так же, возможно, есть возможность добавить функцию “следуюзая строка от метки” для вариантов, когда есть жесткая метка, например слово Адрес, но сам адрес начинается с новой строки и не имеет жесткой метки окончания.
Спасибо
Подумаем, что можно сделать.
Добрый день, Артем. Огромное спасибо! Очень полезный для меня урок! Буквально недавно столкнулся с этой задачей – и вот… решение! Удобный функционал, и интуитивно понятное использование. Спасибо PF!
Но… (ложка дёгтя) продолжая настраивать “правила”, столкнулся с такой проблемой: мне нужно внести изменения во ВСЕ задачи, у которых значение поля равно значению инфоблока. PF почему-то находит первую попавшуюся задачу, удовлетворяющую этому условию, и затем останавливает свой поиск. Остальные задачи остаются без необходимых изменений(( Чем они хуже? Данный вопрос я озвучил в Службу поддержки, мне подтвердили, что ПОКА работает именно так.